ACTU

Faut-il une ordonnance pour acheter en pharmacie en ligne Pharmashopi ?
L'achat de médicaments en ligne est devenu une pratique courante pour de nombreuses personnes cherchant à se procurer des produits pharmaceutiques en toute commodité. Cependant, une question fréquemment posée par ...




GROSSESSE






MINCEUR
PROFESSIONNELS

Femme médecin généraliste : parcours et exercice de la médecine générale
La carrière d'une femme médecin généraliste s'inscrit dans un paysage médical en constante évolution. Embrassant à la fois le rôle de soignante, de conseillère et parfois de confidente, elle arpente ...




SANTÉ
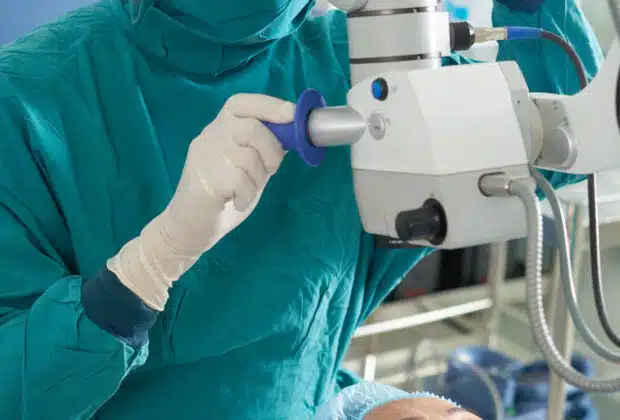
Les urgences ophtalmologiques à Paris de l’institut Daviel : de multiples avantages
Vous avez mal aux yeux ? Quelque chose obstrue votre vue ? Sentez-vous une quelconque gêne dans l’œil ? Plus besoin d’aller à l’hôpital, les urgences ophtalmologiques à ...Bien choisir ses bas de contention : les avantages d’un achat optimal
Le problème veineux est une pathologie qui touche aussi bien les hommes que les femmes. Sensation de jambes lourdes, œdème des chevilles ou des mollets, ...Consommation quotidienne de pastilles Vichy : limites et bienfaits
La consommation régulière de pastilles Vichy est souvent associée à la recherche de bienfaits digestifs grâce à leur riche composition en minéraux. Ces confiseries, emblématiques ...Découvrez Mirialis : avantages et fonctionnalités de la plateforme santé
Imaginons un monde où la gestion de la santé est simplifiée grâce à la technologie. Mirialis, une plateforme santé innovante, se trouve au cœur de ...